概要
FIR(有限インパルス応答)フィルタとIIR(無限インパルス応答)フィルタは、オーディオ・アプリケーションで最もよく使われるデジタル信号処理のアルゴリズムです。実際、標準的なオーディオ・システムでは、プロセッサ・コアによる処理時間(演算能力)のうち、かなりの部分がFIR/IIRフィルタの処理に使われます。このことから、DSP製品の中には、FIR/IIR演算向けのハードウェア・アクセラレータを備えているものがあります。各アクセラレータは、それぞれFIRA、IIRAと呼ばれています。これらを使用すれば、FIRとIIRの処理タスクをアクセラレータにオフロードしてコアを解放することができます。その結果、コアには他の処理を担わせることができます。本稿では、これらのアクセラレータの利用方法を紹介します。リアルタイム・アプリケーションの実例のテスト結果を交えながら、アクセラレータの様々な利用モデルの効果を詳細に解説します。
はじめに

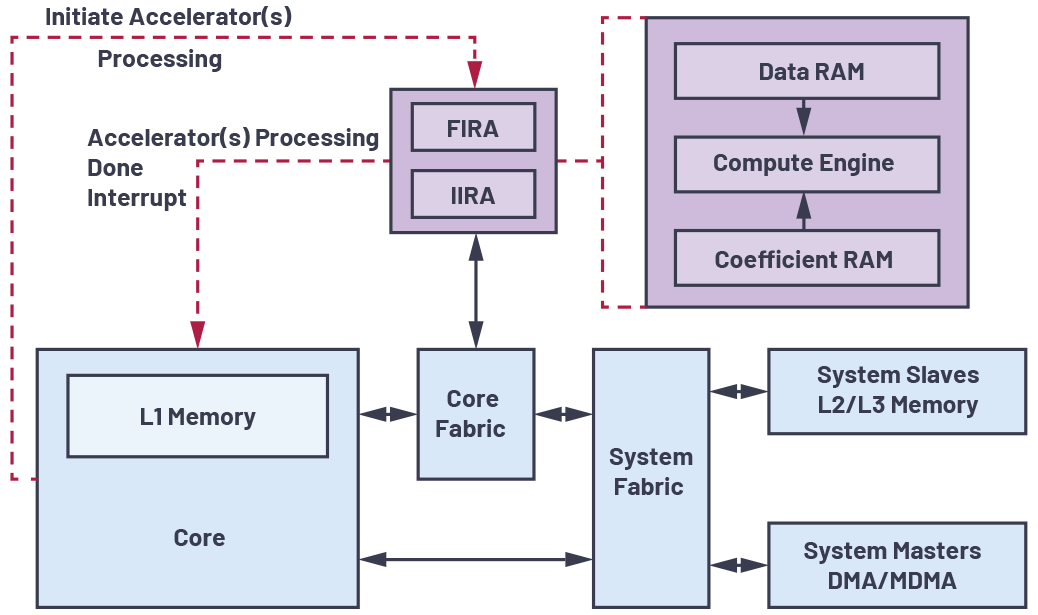
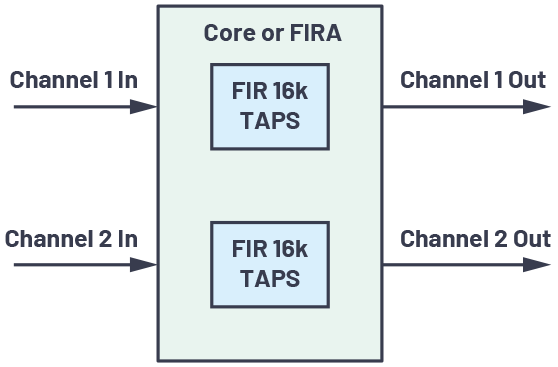
図1は、FIRA/IIRAシステムの構成を簡略化して示したブロック図です。両アクセラレータが、プロセッサ・システムの他の部分やリソースとの間でどのように情報をやり取りするのかを示しています。以下、その詳細を説明します。
- FIRA と IIRA の両ブロックにおいて中核をなすのは、演算用のエンジンです。各エンジンは、積和演算(MAC:Multiply and Accumulate)ユニット、データ用の小さなローカルRAM(データ RAM)、係数用の RAM(係数 RAM)で構成されています。
- FIRA/IIRA の処理を開始するために、コアはチャンネル固有の情報を使って、プロセッサのメモリ内にある DMA(Direct Memory Access) 転 送 制 御 ブ ロ ッ ク(TCB:Transfer Control Block)のチェーンを初期化します。次に、コアはこの TCB チェーンの開始アドレスを FIRA/IIRA チェーンのポインタ・レジスタに書き込みます。そして、FIRA/IIRA の制御レジスタの設定を行い、FIRA/IIRA の処理を開始します。すべてのチャンネルの処理が完了したら、コアに割込み信号が送出され、処理結果となる出力を次の演算で使用できるようになります。
- 理論的には、すべての FIR/IIR のタスクをコアからアクセラレータにオフロードし、コアが他のタスクを並列処理できるようにするというのが最良の状態です。しかし、実際にこれを実現できるとは限りません。コアが更なる処理を加えるためにアクセラレータからの出力を使用する必要があり、並列に完了すべき他の独立したタスクが存在しないといったケースがあるからです。そうした場合に最良の結果を得るためには、アクセラレータの利用モデルとして適切なものを選択する必要があります。
以下では、アプリケーションにおいてFIRA/IIRAを様々なシナリオで最も適切に使用するためのいくつかのモデルを紹介します。
FIRA/IIRAのリアルタイムでの利用

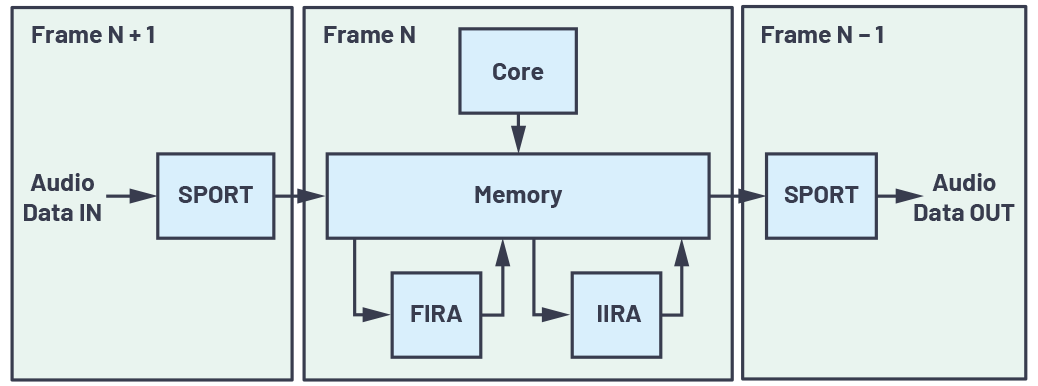
図2は、リアルタイムで処理が行われる標準的なPCM(Pulse Code Modulation)オーディオ・システムのデータ・フローを示したものです。デジタル化されたPCMオーディオ・データの1フレームは、SPORT(同期シリアル・ポート)で受信され、DMAによってメモリに転送されます。フレームNは、フレームN + 1の受信中にコア/アクセラレータで処理されます。先に処理されたフレームN - 1の出力は、SPORTを介してD/Aコンバータ(DAC)に送信され、D/A変換が実施されます。
アクセラレータの利用モデル
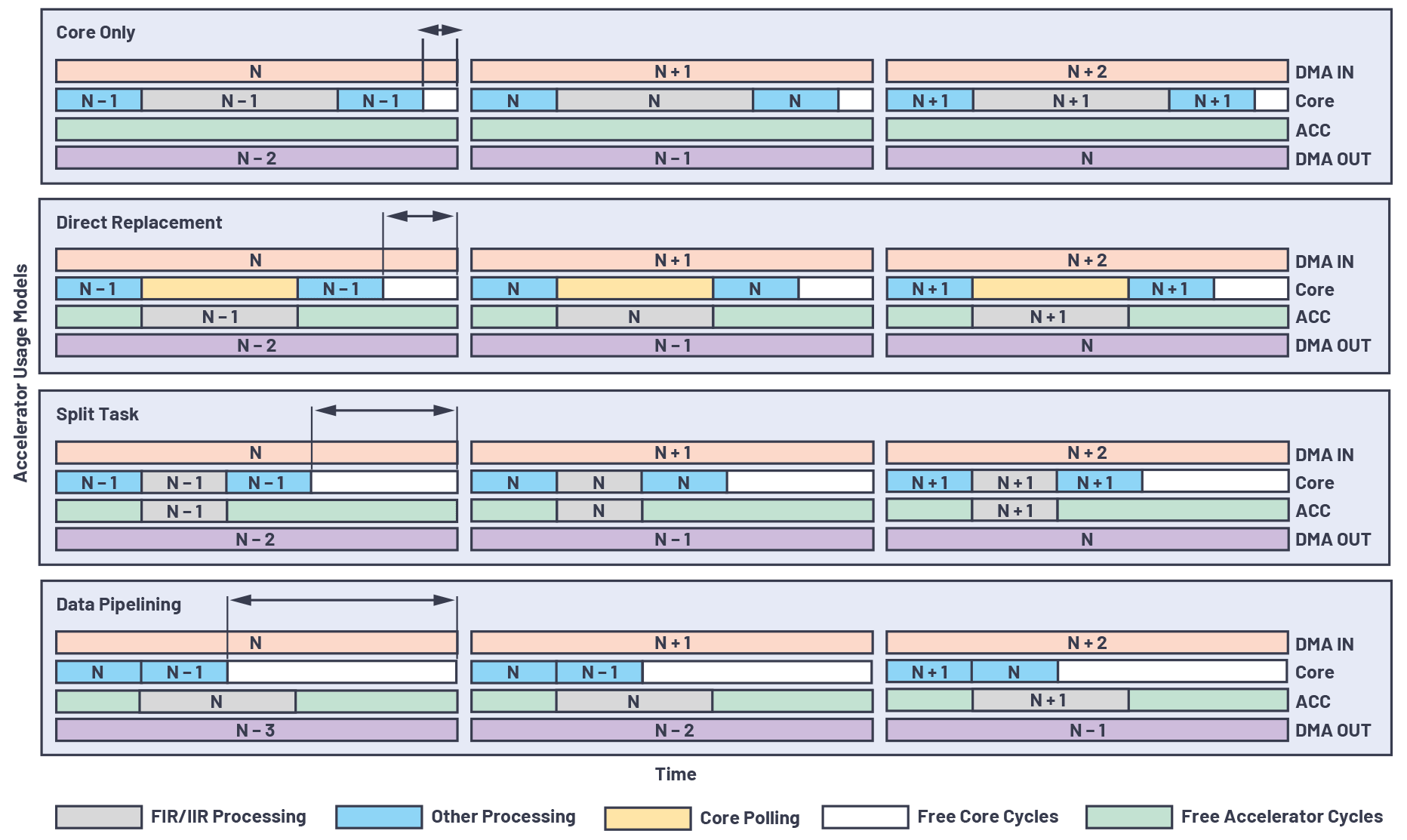
アプリケーションによっては、FIR/IIRの処理タスクを最大限にオフロードし、他の演算のために、可能な限りコアの演算サイクルを節約したいということがあるかもしれません。その場合、条件に応じて、アクセラレータを異なる方法で使用しなければならない可能性があります。高いレベルでは、アクセラレータの利用モデルは、直接置換、タスクの分割、データのパイプライン化という3つのカテゴリに分類できます。
直接置換
以下、直接置換の概要をまとめます。
- コアによる FIR/IIR の処理を直接的にアクセラレータに置き換えます。コアは、アクセラレータによるジョブの完了を待つだけです。
- このモデルは、アクセラレータの方がコアよりも高速に処理を実行できる場合にのみ有効です。つまり、有効なのは FIRA を使用する場合だけです。
タスクの分割
続いて、タスクの分割について説明します。
- FIR/IIR の処理タスクをコアとアクセラレータに分割して実行します。
- このモデルは、特に並列処理のために複数のチャンネルを使用できる場合に有用です。
- タイミングの概算見積もりに基づいて、コアとアクセラレータがほぼ同時にタスクを完了するよう、両者にすべてのチャンネルを分配することができます。
- 図 3 に示すように、直接置換のモデルを使用する場合と比較すると、この利用モデルでは、コアにおいて、より多くの演算サイクルを節約することができます。
データのパイプライン化
最後に、データのパイプライン化について説明します。その概要は、以下のようになります。
- コアとアクセラレータの間のデータ・フローは、両者が異なるデータ・フレームの処理を並行して行えるようにパイプライン化することができます。
- 図 3 に示すように、まずコアはフレーム N を処理し、続いてアクセラレータにこのフレームの処理を開始させます。その後、コアは、前のイテレーションでアクセラレータによって生成されたフレーム N - 1 の出力の処理を並列に継続実行します。このシーケンスにより、出力の遅延の増大という犠牲を払うことになるものの、FIR/IIR の処理タスクをアクセラレータに完全にオフロードすることが可能になります。
- パイプラインの段数と出力の遅延は、処理チェーン全体における FIR/IIR の処理段数に応じて増加することがあります。
図3は、アクセラレータの各利用モデルについてまとめたものです。オーディオ・データのフレームが、DMA入力、コア/アクセラレータによる処理、DMA出力という3つの段の間を通過する様子を表しています。また、各モデルを利用してFIR/IIRの処理をアクセラレータに完全/部分的にオフロードすると、コアのみを使用するモデルと比較して、コアの演算サイクルの節約量にどのような差が出るのかということも見て取れます。

SHARCプロセッサのFIRA/IIRA
アナログ・デバイセズのSHARC®プロセッサ・ファミリの中には、FIRAとIIRAを内蔵しているものがあります。以下に、そうした製品を列挙します。
各製品は、同一世代のFIRA/IIRAを搭載しているわけではありません。また、演算速度もそれぞれに異なります。ただ、基本的なプログラミング・モデルは、ADSP-2156xの自動構成モードを除けば同一です。いずれの製品も、FIRAは4個のMACユニット、IIRAは1個のMACユニットを備えています。
進化したFIRA/IIRAを備えるADSP-2156x
ADSP-2156xは、SHARCファミリの最新製品です。1GHzで動作するシングルコアと、同じく1GHzで動作可能なFIRA/IIRAを備える初の製品です。
性能の改善
ADSP-2156xのFIRA/IIRAにより、従来品であるADSP-SC58x/ADSP-SC57xと比べて様々な改善が得られています。例えば、演算速度は8倍に高まっています(125MHzのSCLKから1GHzのCCLKへ)。また、専用のコア・ファブリックを用いてコアとアクセラレータを緊密に統合しているため、コアとアクセラレータの間で行われるデータ/MMR(Memory Mapped Register)へのアクセスに伴う遅延を低減できます。機能の改善
ADSP-2156xでは、アクセラレータの処理に必要なコアの介入を最小限に抑えるために、ACM(Abstract Control Model)をサポートしました。これにより、以下に示す新たな特徴が得られています。
- ダイナミック・タスク・キューイングを実行するために、アクセラレータを停止することができます。
- チャンネル数に制限はありません。
- トリガの発生(マスタ)とトリガのウェイト(スレーブ)に対応できます。
- 各チャンネル向けに選択的な割込みを発生させることが可能です。
性能評価の結果
このセクションでは、2つのユースケースにおけるADSP-2156xの評価結果を示します。対象としたのは、複数のチャンネルを使用するリアルタイムのFIR/IIR処理です。同製品の評価ボード上でアクセラレータの各利用モデルを用いて処理を行い、それぞれの性能を評価しました。
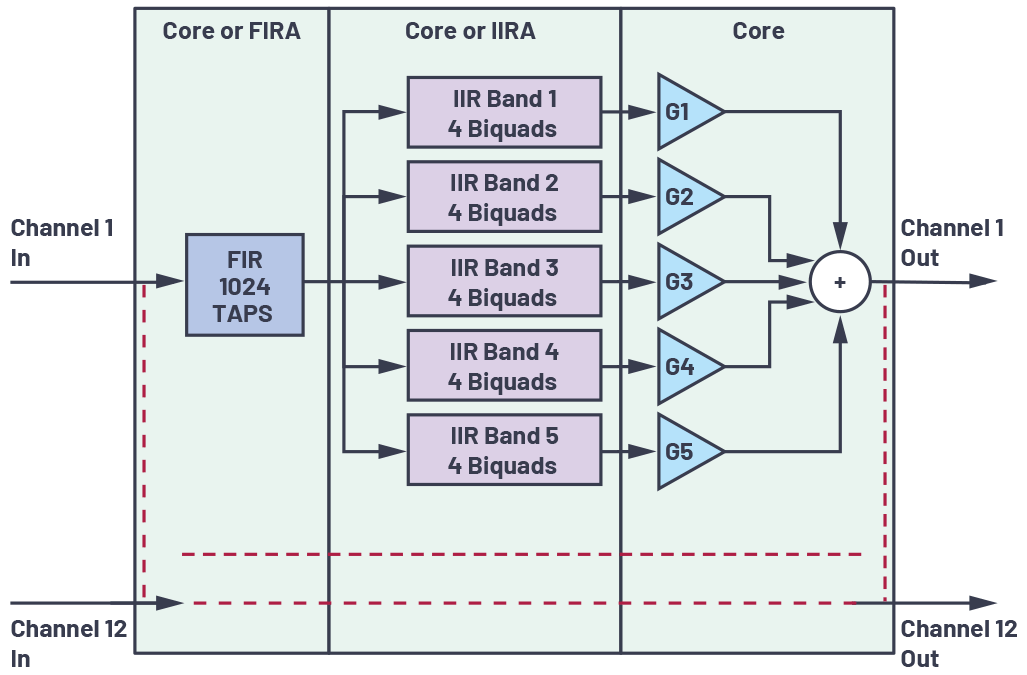
ユースケース1
図4にユースケース1のブロック図を示しました。サンプリング・レートは48kHz、ブロック・サイズは256サンプルです。タスクの分割モデルにおけるコアとアクセラレータのチャンネル比は5:7としました。
表1は、各利用モデルにおけるコアとFIRA/IIRAのMIPS値を、コアのみのモデルにおけるMIPS値と比較したものです。併せて、節約できたコアのMIPS値と、利用モデルごとの出力遅延の値も示してあります。ご覧のとおり、アクセラレータを用いてデータのパイプライン化を利用した場合、1ブロック(5.33ミリ秒)の出力遅延という犠牲を払うことになるものの、コアにおいて最大335MIPSの節約を実現できることがわかります。また、直接置換とタスクの分割を利用した場合、出力遅延を増加させることなく、それぞれ98MIPSと189MIPSの節約を達成できます。

| 利用モデル | コアのMIPS値 | FIRAのMIPS値 | IIRAのMIPS値 | コアのMIPS値の節約量 | 利用モデルによる遅延〔ミリ秒〕 |
| コアのみ | 337 | 0 | |||
| 直接置換 | 239 | 162 | 75 | 98 | 0 |
| タスクの分割 | 148 | 96 | 44 | 189 | 0 |
| データのパイプライ化 | 2 | 161 | 75 | 335 | 5.33 (1フレーム) |
ユースケース2
図5にユースケース2のブロック図を示しました。サンプル・レートは48kHz、ブロック・サイズは128サンプルです。タスクの分割モデルにおけるコアとアクセラレータのチャンネル比は1:1としました。
表1と同様に、表2にこのユースケースの評価結果をまとめました。アクセラレータを用いてデータのパイプライン化を利用した場合、1ブロック(2.67ミリ秒)の出力遅延という犠牲は払うものの、コアにおいて最大490MIPSの節約を実現できます。タスクの分割を利用した場合、出力遅延を全く増やすことなく、234MIPSの節約を達成できます。ここで1つ注意すべきことがあります。それは、ユースケース1とは異なり、コアでは時間領域の処理ではなく、周波数領域(高速畳み込み)の処理を行っているという点です。1チャンネルの処理に要するコアのMIPS値がFIRAによる処理のMIPS値よりも小さく、直接置換のモデルを利用した場合には、コアのMIPS値の節約量が負の値になります。

| 利用モデル | コアのMIPS値 | FIRAのMIPS値 | コアのMIPS値の節約量 | 利用モデルによる遅延〔ミリ秒〕 |
| コアのみ | 493 | 0 | ||
| 直接置換 | 515 | 511 | –22 | 0 |
| タスクの分割 | 259 | 257 | 234 | 0 |
| データのパイプライン化 | 3 | 511 | 490 | 2.67(1フレーム) |
まとめ
本稿で説明したように、所望のMIPS値と処理プロファイルを実現するための手段として、アクセラレータの様々なモデルを利用することができます。また、本稿では、ADSP-2156xを使用した場合、FIRA/IIRAに対してコアのMIPS値をどれだけオフロードできるのか評価した結果も示しました。
参考資料
Sanket Nayak、Mitesh Moonat「Engineer-to-EngineerNote EE-408: Using ADSP-2156x High Performance FIR/IIRAccelerators(EEノート EE-408:ADSP-2156xが備える高性能FIR/IIR用アクセラレータの使い方)」Analog Devices、2019年8月

