要約
このアプリケーションノートでは多くの回路をExcel®スプレッドシートを使用して回路設計者が大局的な統計解析を行う簡単なテクニックについて説明しています。歩留まり解析で使われるランダム部品定数の生成方法を示します。確率分布関数(pdf)と累積分布関数(cdf)が説明されています。特別な場合は、簡易なテクニックで均一に分配された乱数と、測定されたcdfを使って、任意に分布乱数を生成します。これらのテクニックは実際の回路動作を予測し、高い製造歩留りを得るためにも貴重なものとなります。
はじめに
現実上で動作する回路を設計することは簡単なことではありません。仕様目標を満たす回路の設計だけでは不十分です。部品間の現実的なばらつきを含んだ予想される条件の範囲内で回路の動作を正確に予測することも重要です。このプロセスを一般的に回路歩留まり解析といいます。この動作をよく理解することができれば、結果として設計者は予想される製造誤差内で動作する回路や部品を効果的に選択することができます。
回路のパラメータが変化しても正常に動作する回路は、組み立て、テスト、およびサポートのコストが安価になるということもよく知られています。
このアプリケーションノートでは、歩留りの解析(様々な部品定数で作られたどれだけ多くの回路が仕様を満たすのかの予想)を行うための誤差の扱い方を記しています。有効な歩留り解析をするには以下が必要です。
- 重要な部品や浮遊容量などの正確な回路モデル
- 部品の種類における正確なモデル
- パス/フェイルの定義や仕様
表1. 歩留り解析の方法
| 歩留り解析 | ||
| ツール | テクニック | 最適な使用 |
| SPICE | 複数のシュミレーション | 回路動作の裏付け。洞察を得るには不適切 |
| SPICE | SENS感度解析 | 重要な部品の予測に適切 |
| 正確なクローズドフォーム分析 | 回路の性能を決定づける方程式を使い感度解析をする。部品の誤差を表す式と感度から仕様を満たす確率を計算する。 | 簡単な問題にのみ適用。用いられているテクニックの理解の助けとなる。 |
| Microsoft® Excel、MathCAD | 製造データからcdfを作成し、それによって回路モデルを作る | 中程度の複雑さ。現実のデータを扱い、問題を予見しやすい |
このアプリケーションノートではMicrosoftのExcelを使用した歩留り解析の方法を記します。確率分布関数(pdf)のようないくつかの基本的な歩留り解析の概念について説明します。希望する確率分布にフィットするランダムな部品定数の発生の仕方について説明します。
部品定数と設計のための方程式によって決まる歩留り
部品によって回路は成り立っています。回路はこれらの部品を組み合わせて作り、回路全体としての動作はある種のルールや回路方程式によって決まります。歩留り解析を行うためには、設計者は部品のばらつきと設計方程式について知っていなければなりません。
一例として下記の図1の簡単なゲイン回路を見てみましょう。このオペアンプのゲインはRfとRgの抵抗値を知ることにより計算されます(この解析では理想的なオペアンプとします)。現実にはこの回路を数百回作った場合RfとRgの部品定数がそれぞれ異なります。回路をテストすると、ゲインはそれぞれが違った値になります。この回路例では部品のばらつきは抵抗値の誤差になります。ゲインの設計式は以下になります。
Gain = - Rf/Rg一例として、もしRf = 1kΩでRg = 1kΩならばゲインはちょうど-1になるはずです。
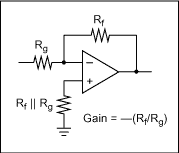
図1. 反転オペアンプの例
最終的にこの回路の仕様は、gain = -1 ± 0.1V/Vのようになるでしょう。
部品PDFとCDF
一般に、設計者は、ある一つの部品の値を予測することはできません。しかしながら、経験上多数の部品がまたはどれだけ多くの製品がどのような挙動をするかを予測することができます。そのことを表すためにpdfつまり確率分布関数が使われます。
pdfは、特定値が生じる確率に対するランダムな変数Xのありうる値xを記す曲線または関数です。一例としてこの簡単な回路で、抵抗群内に抵抗を見いだす確率に対する抵抗値Rfを記しています。
cdfは累積分布関数です。これはランダムな変数Xがある値x以下になる確率です。すなわち、pdf分布があれば、cdfを積分により推定することができます。2つのパラメータ、平均値(中心値)と標準偏差(ピーク値の幅内)で定義されたガウス分布または標準分布のpdfはおそらく既に使ったことがあるでしょう。標準分布のpdfとcdfを図2に示します。
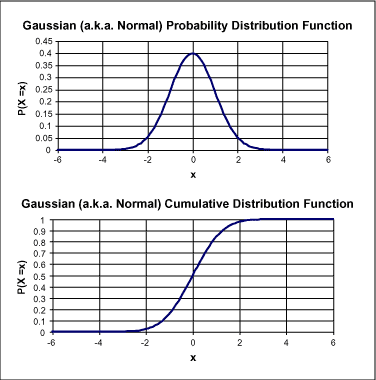
図2. PDFとCDFの例
標準分布は現実での多くの状況に適合し、数学的に簡単に扱うことが可能です。しかし注意してください!標準分布は特殊な状況を表せないかもしれません。例えば、20%精度の抵抗の中から5%精度の抵抗がすべて抜き取られ売却されていたというようなこともあるでしょう。この際の実際のpdfは図3のように見えるでしょう。
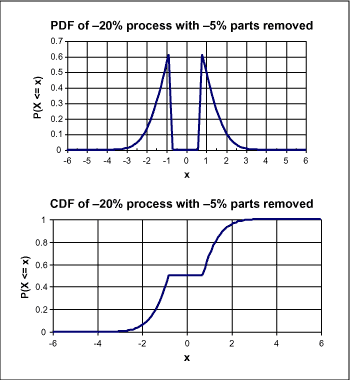
図3. ソーティングされた部品の分布
この分布では、測定された抵抗値が抵抗のラベルに書いてある値と一致する確率はゼロです! 標準分布の部品定数を使って作ったときに比べると回路の動作はかなり悪くなるでしょう。5%の抵抗を使って作った回路設計者は、分布の幅が小さいために期待以上の動作をしていることに気がつくことでしょう。
多くの分布は有用であり、分布モデルの選択は重要です。決して標準分布の関数だけに拘らないでください。
Excelでランダムな部品定数を作る
一連のランダムな値を使って生産工程での抵抗値を表すことができます。これらの値を回路方程式と合わせて用いることにより、回路のゲインを知り、仕様と比較したり歩留りを求めるために利用できます。下の図に例を示します。20台作ると、±20%のゲインの仕様に対して歩留りは80%となります(結果は生産回数ごとにやや異なります) 。
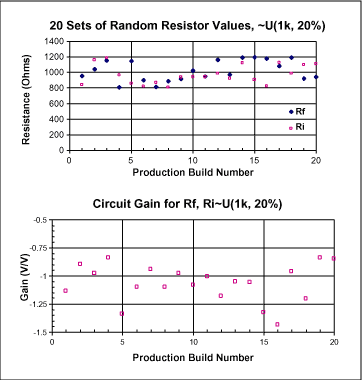
図4. ランダムな抵抗値の生成とその結果のゲイン
上の解析では各抵抗値に均一に分布した乱数を使いました。均一分布の場合、抵抗値は2つのリミット値間の値を同じ確率でとります。この抵抗値を生成するにはExcel*¹を使ったいくつかの方法があります。ツール![]() データ解析
データ解析![]() 乱数の生成、またはRAND()の使用(Excel内のRANDBETWEEN()関数も参照してください)。RAND()あるいはRANDBETWEEN()関数技術を使う場合、スプレッドシートが計算するたびに(F9を押す)値が再生成されます。
乱数の生成、またはRAND()の使用(Excel内のRANDBETWEEN()関数も参照してください)。RAND()あるいはRANDBETWEEN()関数技術を使う場合、スプレッドシートが計算するたびに(F9を押す)値が再生成されます。
RAND()は、0以上および1未満の乱数を出します。1以上でありながらb未満の乱数を出すには、RAND() × (b-a) + aを使ってください。RANDBETWEEN(a,b)を使うと、aとbが両方整数であれば、a以上およびb以下の整数を出せます。aとbが整数ではない場合、RANDBETWEEN(a,b)でaとbの間の整数が出ます。
残念ながら、大多数の部品は均一分布以外の分布に従います。しかしながら、この型式の解析は最悪の特性を求めるためには速くて便利です。
PDFとCDFの標準分布
Excelには、より現実的なpdfを生成するのを補助するその他多くの関数があります。標準分布またはガウス分布を生成するにはNORMDIST()を使います。一例として"=NORMDIST($A7,0,1,FALSE)"はA7セルxの値に対して平均値 = 0、標準偏差 = 1で計算された標準分布確率を返します。
標準偏差(時としてシグマと呼ばれます)はpdf関数のピークの幅を表し、2次導関数の極性が変わる点に相当します。これは図2のpdfを算出するのに使用しました。"FALSE"を"TRUE"へ変えることによってcdfの値が得られます。
他に詳しい情報がない場合、部品の精度は±3の標準偏差であると仮定します。一例として、±10%の誤差を持つ部品の標準偏差は公称値に対して±10/3 = ±3.33%となります。
cdfとpdfは標準乱数を生成しますが、ランダム部品定数は得られません。理想的には標準分布にフィットする乱数を返す"RANDNORM()"のような関数が欲しいところです。
標準分布を持つ乱数の生成
上記のように、ExcelにはRANDNORM()関数がありませんが、関数の追加機能により必要な機能を得ることが可能です。公称値1kΩで±20%の分布を持つ10個の抵抗の通常値を生成させるには以下のステップをたどります。
- 公称平均値1kΩで、標準偏差が±20%の1kΩ / 3 = ±200/3 = ±66.67Ω
- 関数の追加機能によりリストを生成します。ツール
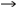 データ解析乱数の生成の関数を使います。このダイアログボックスは図5のようになります。
データ解析乱数の生成の関数を使います。このダイアログボックスは図5のようになります。
図5. 乱数生成のダイアログボックス
平均値と標準偏差はステップ1で計算されます。10を入力すると、乱数(値)が生成されます。出力範囲(Output Range)は、Excelに計算値を入れたいスプレッドシート内のセルを示します。結果の出力は図6のようになります。
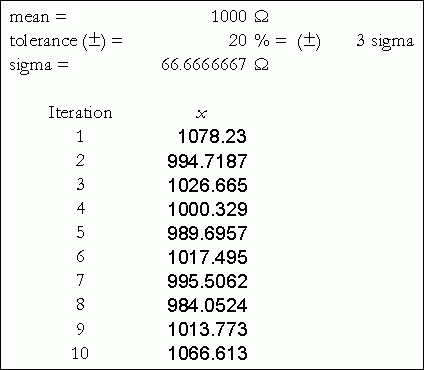
図6. Excelで生成されたランダムな部品定数
他の便利な分布
Excelにはツール![]() データ解析
データ解析![]() 乱数のダイアログボックスで選ぶことのできる様々な分布リストが用意されています。これらはNormal、 Uniform、 Binomial、 Bernoulli、Discrete、およびその他いくつかの形式も含まれています。先に示した均一分布は最悪条件を見つけるための簡単で便利な方法です。Binominalはロジック回路で見られるように(例、1と0) 2つだけの値を持った分布です。統計の本あるいは経験によって状況に応じて正しい関数を選択します。
乱数のダイアログボックスで選ぶことのできる様々な分布リストが用意されています。これらはNormal、 Uniform、 Binomial、 Bernoulli、Discrete、およびその他いくつかの形式も含まれています。先に示した均一分布は最悪条件を見つけるための簡単で便利な方法です。Binominalはロジック回路で見られるように(例、1と0) 2つだけの値を持った分布です。統計の本あるいは経験によって状況に応じて正しい関数を選択します。
しかしながら、この分布が状況に適合しない場合にはどうすべきでしょうか?オリジナルの乱数を生成すればよいのです!次のセクションではこのことについて説明します。
製造情報に基づいた乱数の作り方
用意されている関数あるいは標準のpdf関数が回路の状況に全く合致しない場合があります。さらには、ソーティングされた抵抗の場合(図3参照)にあるように標準的でない分布がもたらす影響は非常に大きなものになります。
このような状況では製造テストデータから直接分布を作るか、計算によって分布を作ります。そしてその分布に沿った乱数を生成することで歩留まりの解析を行います。
そのような分布や乱数の生成にはいくつかの手順が必要となります(図7参照) 。
- 実際の部品を多数測定するか、あるいは計算等によってデータを作成する。おそらくこれらの情報は受け入れ検査などのプロセスから入手することができます。このデータはpdfを作成するのに利用されます。
- データのヒストグラムを作り、サンプルの総数によって標準化する。これはすなわち、確率の総和が1となることと同じです。この標準化されたヒストグラムが、乱数に沿うpdfとなります。
- pdfを積分してcdfを作ります。その最大値の1に単調増加的に到達することを確認します。
- 0と1の間の均一分布乱数y、y~UY(0,1)を発生します。
- 均一分布乱数値をcdfがy = P(X ≤ x)となる点でのインデックスとして使い、xの値を読みます。
- ステップ4と5を繰り返し、必要なだけの乱数値xを生成します。
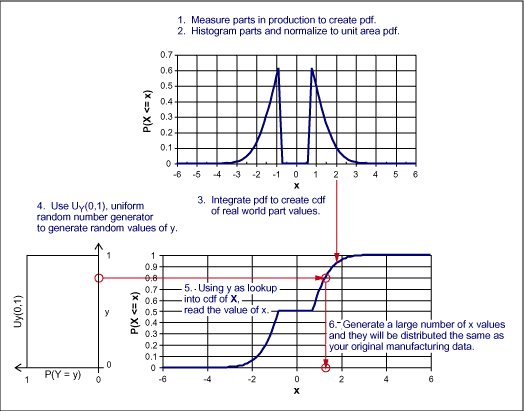
図7. 生産データに一致する乱数値の生成
結論
このプリケーションノートでは歩留り解析に用いるランダムな部品定数の生成の方法を見てきました。一般的な分布はExcelに予め機能として備わっているため速く簡単に生成することができます。特別な場合に対しても均一分布の乱数を測定されたcdfとともに使い、任意の分布の乱数を発生する簡単なテクニックが使えることを紹介しました。
¹2003バージョン以降のExcelを使っている場合は、Add-InとAnalysis ToolPakを起動していることをご確認ください。このパスを使用してください:Data ![]() Analysis Group
Analysis Group ![]() Data Analysis
Data Analysis ![]() Random Number Generator
Random Number Generator
この記事に関して
{{modalTitle}}
{{modalDescription}}
{{dropdownTitle}}
- {{defaultSelectedText}} {{#each projectNames}}
- {{name}} {{/each}} {{#if newProjectText}}
-
 {{newProjectText}}
{{/if}}
{{newProjectText}}
{{/if}}
{{newProjectTitle}}
{{projectNameErrorText}}
最新メディア 20